アプリケーション情報を追加しました
新規アプリケーションとして以下を追加いたしました。
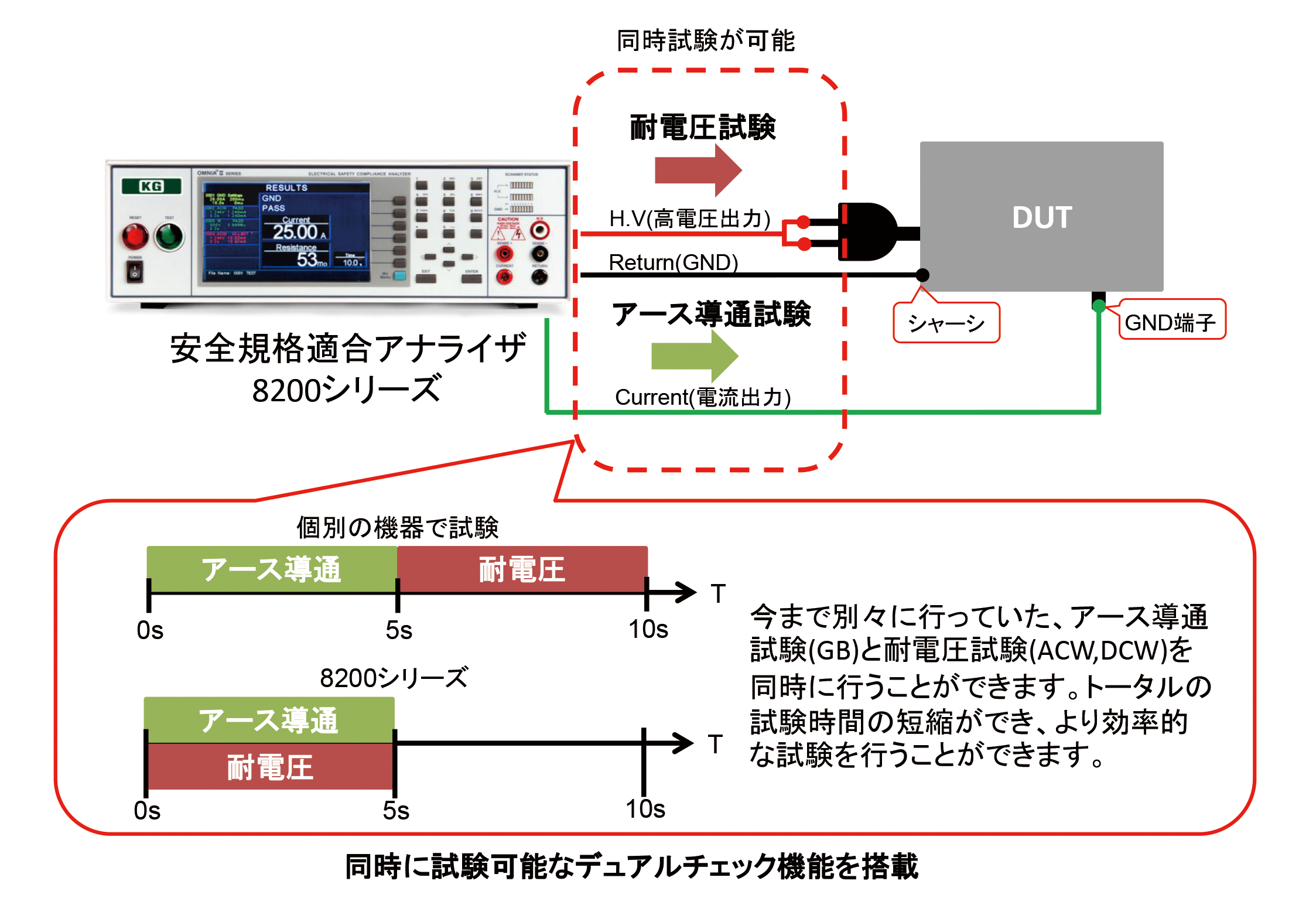
供試製品(DUT)へ通電中に耐電圧試験可能な安全試験器
アース端子を持った電子機器に対して、耐電圧試験の他にアース導通試験の実施も必要となります。このアプリケーションでは、当社安全規格適合アナライザ8200シリーズを使ったより効率的な試験方法についてご紹介致します。
計測技術研究所はパワエレを通じて環境保全に貢献してまいります
新規アプリケーションとして以下を追加いたしました。
アース端子を持った電子機器に対して、耐電圧試験の他にアース導通試験の実施も必要となります。このアプリケーションでは、当社安全規格適合アナライザ8200シリーズを使ったより効率的な試験方法についてご紹介致します。
